
Azure Spring Clean - Azure Storage and Backup Lifecycle Best Practices
Community ·
Welcome to Day 13 of the Azure Spring Clean event. Special thanks to Joe Carlyle and Thomas Thornton for organizing this great event and allowing me to contribute. I am very excited to add to the #AzureFamily contribution this month with some best practices on Storage and Backup lifecycle management within Azure.

Understanding the foundation of cloud services is important to this discussion. I will use the “three legged stool” as an analogy for both cloud consumption costs, and storage within this discussion. As far at the three legs for cloud consumption of infrastructure, they are compute, networking and storage. Yes, there are platform services that incur costs (i.e. app services and database services), but they fundamentally are based on the “three legs”. Therefore, to optimize your costs within the cloud, you must optimize the use of these three legs. This article will focus on the storage aspect of this stool.
In addition to strictly cost, when thinking about data, it can have its own “stool”, with the three legs being cost, security, and availability. We could continue to bring other “stools” into the mix, such as the C-I-A triad of confidentiality, integrity, and availability, but that is not the topic of this article. As we talk about storage cost, security, and availability, we begin to determine and design the Data Lifecycle of our storage accounts to manage these three “legs”. So, let’s get into the details as they pertain to virtual machine storage, storage accounts, databases, and lastly, logging.
Virtual Machine Storage
Within an IaaS designed environment, with virtual machines and managed disks, Azure does not have the level of data lifecycle capabilities that we will discuss within Storage Accounts. Virtual Machine storage is governed primarily by Azure Backup.

Once an Azure Backup service has been created, you now have the ability to create a backup policy that will be the standard for ensuring the availability of both your applications and your data.

When creating the Backup policy for your virtual machine, there is the option to use the Daily policy, Default policy, or to set your own. Both the Daily and Default are a daily backup frequency with the Daily retaining snapshots for 2 days and 180 days of backups. The Default policy retains only 30 days of backups. A best practice would be to create your own policy that aligns with the organizations business continuity and disaster recovery plan, as well as any data retention requirements from a legal perspective.

The best part about creating your own backup policy is that you can also control the amount of storage use in your backups. Where the built-in policies simply retain daily backups, a custom policy allows you to set up daily, weekly, monthly, and yearly policies for backup and retention. This decreases the amount of backups in storage while maintaining availability of your data over an extended period of time. A typical best practice here is to create a policy that retains a six days of weekly backups, three weekly, eleven monthly, and the number of yearly that may be required by any regulatory retention requirements. For example, if the server is holding your financial application and data, you may want to keep seven yearly backups at a minimum to adhere to US IRS tax requirements.
Storage Accounts
Within a Storage Account, Azure has some different ways to manage data lifecycle in order to protect cost and availability. The first way that this is done with with the replication of the storage account. Azure continues to create multiple ways to protect data availability by added ways to replicate that are inherent to the storage account. When creating a storage account, a primary selection point is Replication. There are currently four (4) methods within GA release (LRS, ZRS, GRS, and RA-GRS) and two (2) in additional in preview (GZRS and RA-GZRS).
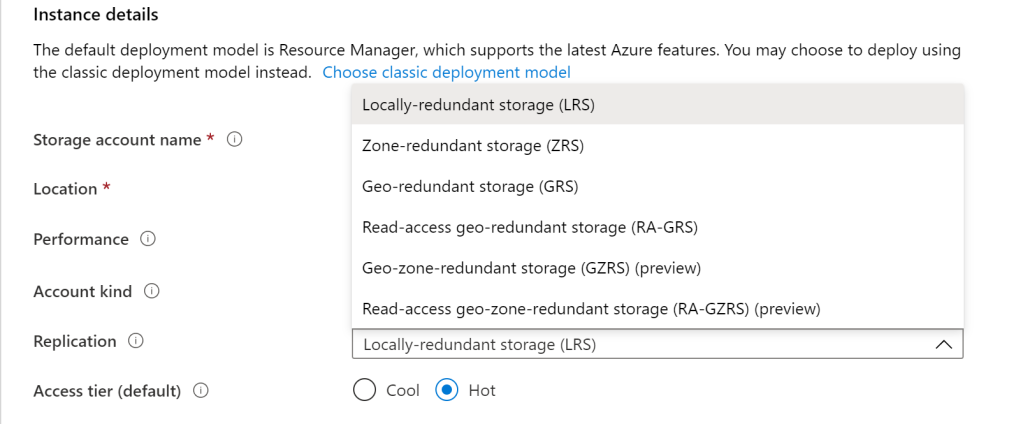
Not all of these options are available in all regions currently, so make sure that you verify availability in your preferred region. The key points to understand with replication is that these are exact copies of your data. This means if a copy of you data becomes corrupt, all of the replications of that data become corrupt. Therefore, the replication policy should be utilized in conjunction with a backup policy. More information on storage account replication and SLA’s can be found here: https://docs.microsoft.com/en-us/azure/storage/common/storage-redundancy Something to understand here is that storage cost will increase depending on the replication tier, with GRS costing 2x that of LRS, this is due to six copies of the data being stored with GRS and three copies with LRS. ZRS replication options fall in between the two.

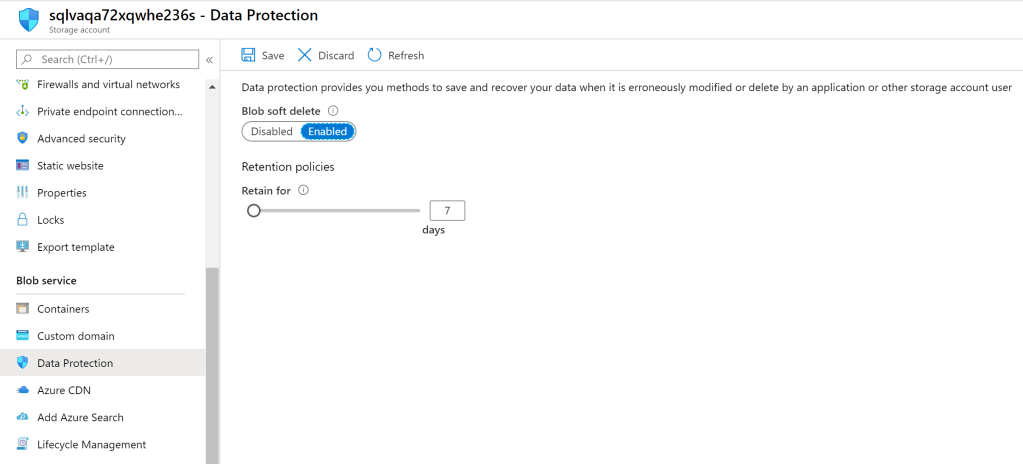
After building a storage account with the desired, it is recommended that a Data Protection level is set for your Blob storage account. Data Protection works in the same manner as the Recycle Bin does on your computer. If enabled and a file is deleted, it will retain that deleted copy for the amount of time that you select, from 1 day to up to a year. Enabling this feature alleviates the concern of accidental deletion of data within the storage account.
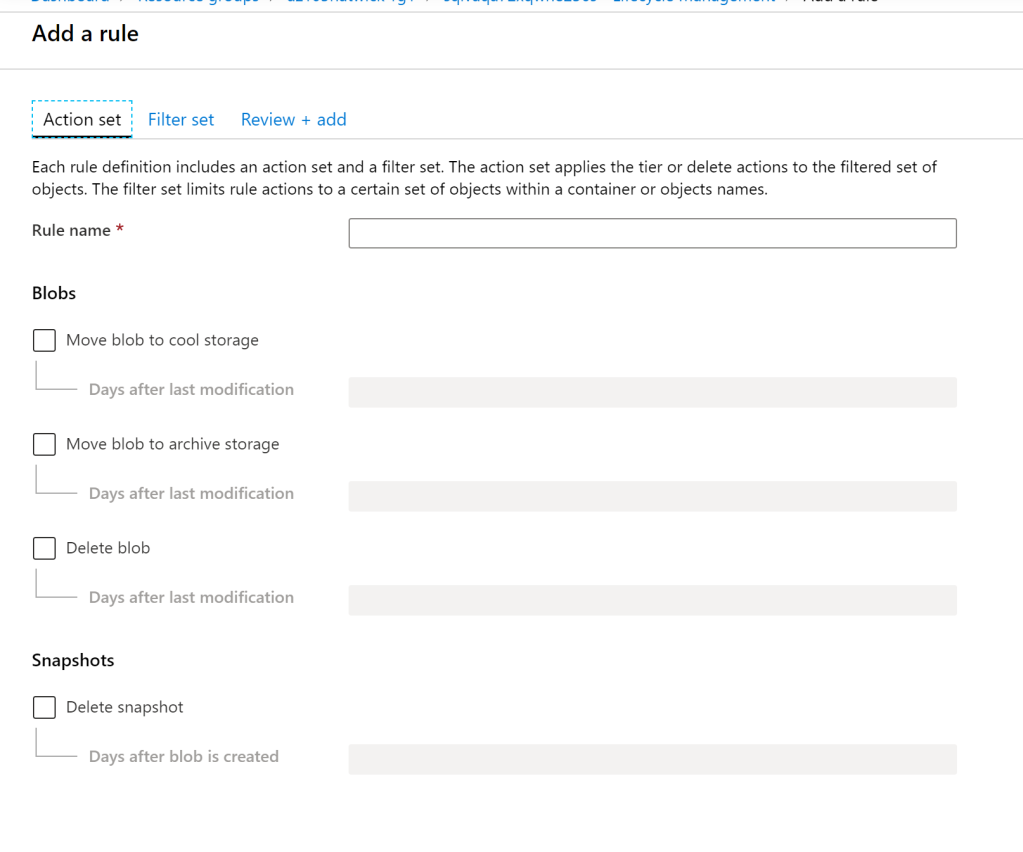
The last point that will be covered in this section is storage account tiers. Azure and other Public cloud providers have multiple tiers of storage that are at different per GB rates that can significantly decrease storage costs. Microsoft Azure has three tiers: hot, cold, and archive. Cold storage is 50% the cost of hot storage, and archive storage is 10% the cost of cold storage. When creating a storage account, you can specify whether the account itself is a Hot or Cold storage account, or you can enable Lifecycle Management within the Blob Service of the storage account. Setting up data lifecycle management within the Azure environment can move data that is not being accessed to these storage tiers automatically, saving money in an area that costs continue to grow, while also allowing your organization to maintain availability and compliance. Blobs can be moved from hot to cool, then to archive, and even set to be deleted based on the days since the data was last modified. Managing the lifecycle of snapshots can also be set within these rules.
Data Lifecycle Management provides flexibility to your data cost, security, and availability. Different storage accounts can adhere to different rules based on the type of data being stored within the accounts.
Databases
For context in this section, we are referencing Databases as a Platform Services. Databases software installed on a Virtual Machine instance would fall under the virtual machine section referenced earlier in this article. Utilizing Platform Database services, such as SQL and CosmosDB, removes the need to manage the compute infrastructure and simply work with the data and connections to applications.
Microsoft Azure has built in resiliency within these platforms for data and security. The primarily point of configuration within an Azure Database is to assign a paired region to the primary database for failover. The example below shows a SQL Database in Central US paired with West US. Creating these pairings along with utilizing Business Critical or Premium database subscriptions, provide a strong SLA and recovery point for your database of 99.995% availability, 5 second RPO, and 30 second RTO (https://azure.microsoft.com/en-gb/support/legal/sla/sql-database/v1_4/).

Additional security settings can also be configured within SQL Database for advanced protection, such as Advanced Threat Protection and Transparent Data Encryption. https://docs.microsoft.com/en-gb/azure/sql-database/
CosmosDB (https://docs.microsoft.com/en-gb/azure/cosmos-db/) is a globally distributed database platform that provide inherent replication and resilience. This includes 99.999% read and write availability when configured with multiple writeable regions (https://azure.microsoft.com/en-gb/support/legal/sla/cosmos-db/v1_3/).
Log Storage
The final component of data lifecycle planning and design is the storage of log files. Log files are important from a support and auditing standpoint, and they should not be overlooked. The data that can be analyzed from these files may be necessary when determining a cause or reason for a security breach, or possibly activity that has allowed unauthorized changes within the environment. Without these logs, no one would be able to easily track down and remediate issues in a timely manner.
For this reason, log files should maintain their own data lifecycle. Log files are stored within a storage account and, therefore, have the ability to be configured with Data Lifecycle Management rules.
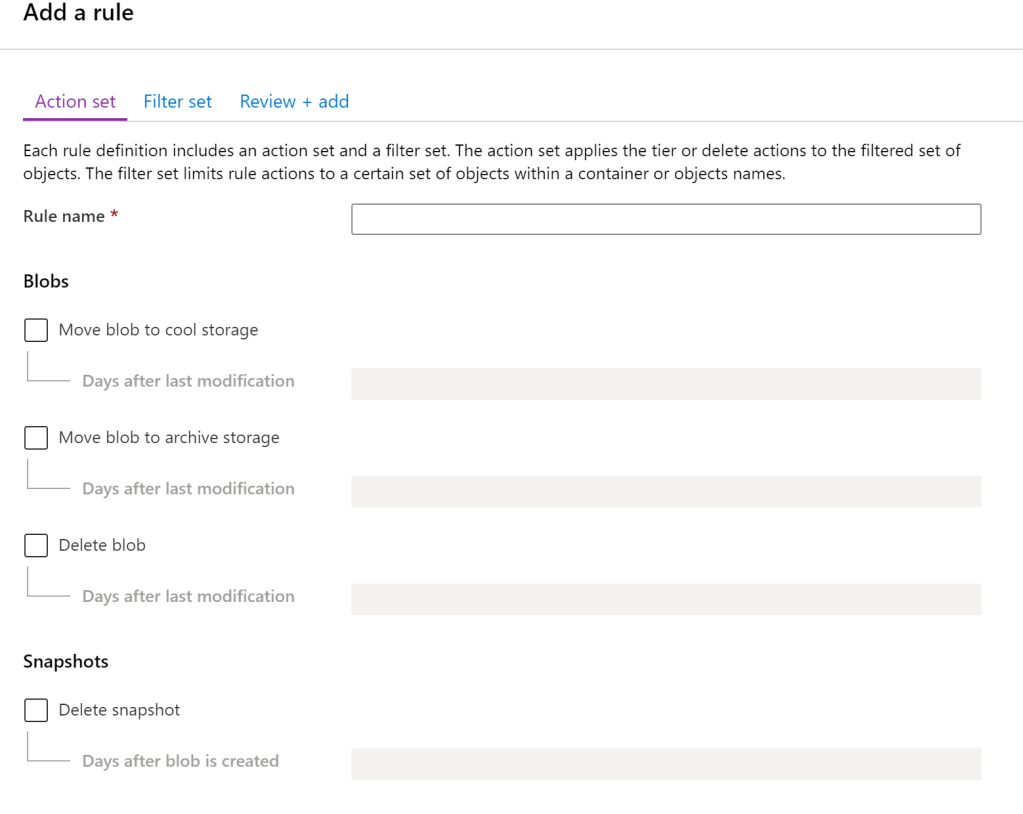
Logs should be not be mixed with other storage accounts, they should have their own storage account and containers configured with their own Data Lifecycle Management rules. Since logs are accessed somewhat infrequently, relative to active files, images, and videos that are used to run the business, they will move through Hot to Cool to Archive more rapidly. It is important to take this into account and understand that accessing files from an Archive can be costly, so log files may require an extended time within Cool storage before being moved to Archive within the lifecycle.
At the beginning of this post, I mentioned the three stool “legs” of data as being cost, availability, and security. Security was mentioned within some of the focused data types and services, but there are keys to security that are important within each section, Data-at-Rest and Data-in-Transit. Azure provides encryption for Data-at-Rest by default on all storage accounts, disks, and databases. For Data-in-Transit, encrypted transmission channels using TLS 2.0 are utilized and access to storage account URLs default to HTTPS.
In closing, Data is an organization’s second most important asset after its people. Compromised or lost data can cause an extreme amount of financial loss. Therefore, it is important to protect the confidentiality, integrity, and availability of that data with a strong defense and data lifecycle plan. Thank you very much.
You can follow me on Twitter @DwayneNcloud or follow this website for regular Azure and Cloud content.
Be sure to check out the other posts for #AzureSpringClean at Azure Spring Clean.